
With the growth of volume and diversity of data in recent years, it has become even more critical for organizations to develop an effective and scalable strategy for data governance and its closely aligned sibling discipline – Master Data Management. The importance of ensuring the security and the quality of data has never been more important than now. Add to that the increased pressures for regulatory compliance and privacy concerns, having a solid approach to data governance is no longer an option, it’s a necessity. In this 2-part blog series, I will discuss how the Data Vault 2.0 System of Business Intelligence addresses these concerns and incorporates both Data Governance and Master Data Management.
Data Security
How you plan to manage your enterprise data security is a critical aspect of an overall data governance strategy. It is often the first area of data governance most teams work on. Making sure you get the right data to the right, authorized, people at the right time is the main challenge for organizations. With the threat of hacks, ransomware, and all manner of data thefts on the rise, organizations who do not plan how they will protect and secure their data are playing with fire.
Data security can no longer be an afterthought. Throwing all of your data into an unsecured data lake is just asking for trouble (the least of which are violations of privacy laws should the data be exposed).
Data Vault was originally developed in the world of highly secret defense department data. That environment required architectures and methods to easily segregate sensitive and classified data from prying eyes. Hence Data Vault 2.0 has methods and principles built into its approach that deal with these scenarios.
The Data Vault architecture and modeling approach makes it easy to segment data based on privacy and security concerns. Because of the granular and atomic nature of Hubs, Links, and Satellites, the data is often naturally segmented. As a best practice, we recommend separating sensitive data from less sensitive data so that is can be more easily secured via various access control methods, whether logical (e.g., RBAC, row access policies, dynamic data masking, etc.) or physical (e.g., separate tables, schemas, or databases).
At the physical level, there are two typical techniques. The first is separating sensitive (e.g., PII, PHI data) from non-sensitive data in the design of Satellites off of a Hub or Link. In this case, we simply put the sensitive attributes in one Satellite and the non-sensitive in another Satellite. Then, using role-based access controls (RBAC), we can easily control who can see and act on that data at the table level.
The second technique is to separate objects with sensitive data into separate containers. In the early days of Data Vault this was done by placing the tables with sensitive data into a separate database on a separate, secured, physical server behind an advanced firewall. In today’s world with the advancements in the cloud (such as Snowflake), it is now possible to achieve this logically with greater ease and without concern about having to manage multiple physical servers in likely separate remote locations. See figure 1 for an example of how it might look using the Snowflake Data Cloud.
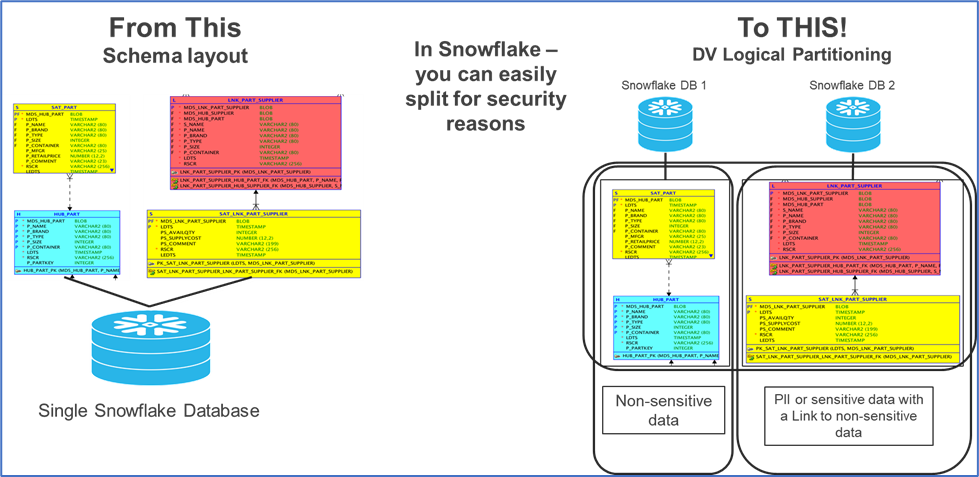
Figure 1 – Separation of Sensitive Data Using Data Vault and Snowflake
Whether using separate physical databases or logical containers in the cloud, you can of course set the RBAC as needed according to your business requirements. In Figure 1, the group that is allowed to see the sensitive data can see both databases and can therefore join sensitive data to non-sensitive data using the Link structure. However, since the Link is hidden in the sensitive database, the users who only have access to non-sensitive data can’t see the Link (or its associated Satellite) so they don’t even know the sensitive data exists (which is a security measure in and of itself).
With this separation of concerns capability, you could split sensitive and non-sensitive Satellites in the same manner (i.e., logically or physically separate databases).
The Business Vault
The Business Vault can also play a role. PITS and Bridges can be set up specifically to segregate the sensitive data. Either structure can be built to only provide access to select tables (and data). Utilizing featured objects like PITs and Bridges within the Information Delivery Layer, it is possible to build separate Business Vaults for either view of the data. You can build one that allows access to non-sensitive data and another that accesses sensitive data. Again, you can use simple RBAC to control who sees which Business Vault and let no one see the underlying Raw Vault.
Another benefit of the DV 2.0 approach is that it is flexible, extensible, and agile. This means that nothing is locked in stone – the architecture, model, and organization of the data can be adapted as requirements change or emerge over time.
In these ways the Data Vault architecture has been able to manage even the most advanced security concerns since its inception and will continue to do so for years to come.
In the next blog, I will discuss Data Quality and how the Data Vault 2.0 system helps in that area.